My research explores the application of probabilistic models of language learning and language processing—broadly Bayesian and neural network models—to longstanding questions in cognitive science, linguistics, and developmental psychology. This includes modeling interaction in child language learning, understanding early linguistic productivity, robust speech processing in adults, the developmental origins and representations of multiple meanings per word, and the quantitative linguistic universals that emerge from the demands of realtime processing.
I also work on a variety of tools and infrastructure projects to enable faster data exploration and reproducible science. I also work on new platforms to gather dense longitudinal data from broader populations, especially for questions regarding first language acquisition.
Modeling Interaction in Child Language Learning
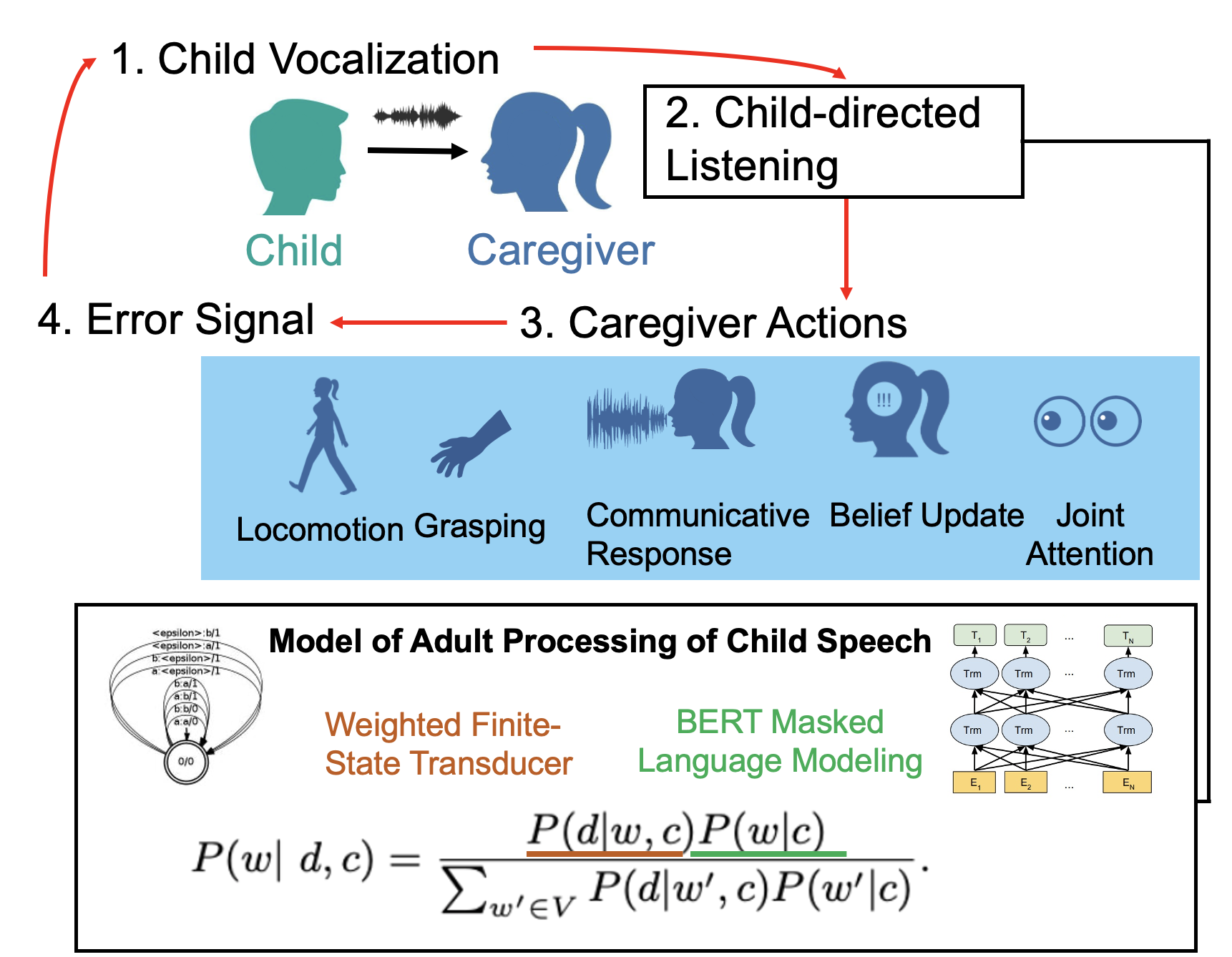
Caregiver Contributions to First Language Learning While the phenomenon of “child-directed speech” has received considerable attention, how adults listen to children is much less well understood. This may be especially important in that adult interpretations (and actions) may be the key to understanding how children’s goal-driven behaviors (like locomotion and grasping) come to include language use. In this work, we show that a Bayesian model of spoken word recognition that implements an advanced neural network-based prior can capture adult interpretations of children’s speech, while a model using only the acoustics fails to account for the meanings recovered by adults. Joint work with Dr. Ruthe Foushee, Dr. Roger Levy and Dr. Elika Bergelson.
Meylan, S.C., Foushee, R., Wong, N., Bergelson, E., and Levy, R.P. (2023). How Adults Understand What Young Children Say. Nature Human Behavior. (pdf)
Meylan, S.C., Foushee, R., Bergelson, E., and Levy, R.P. (2021). Child-directed Listening: How Caregiver Inference Enables Children’s Early Verbal Communication. In Proceedings of the 43rd Annual Meeting of the Cognitive Science Society. (pdf)
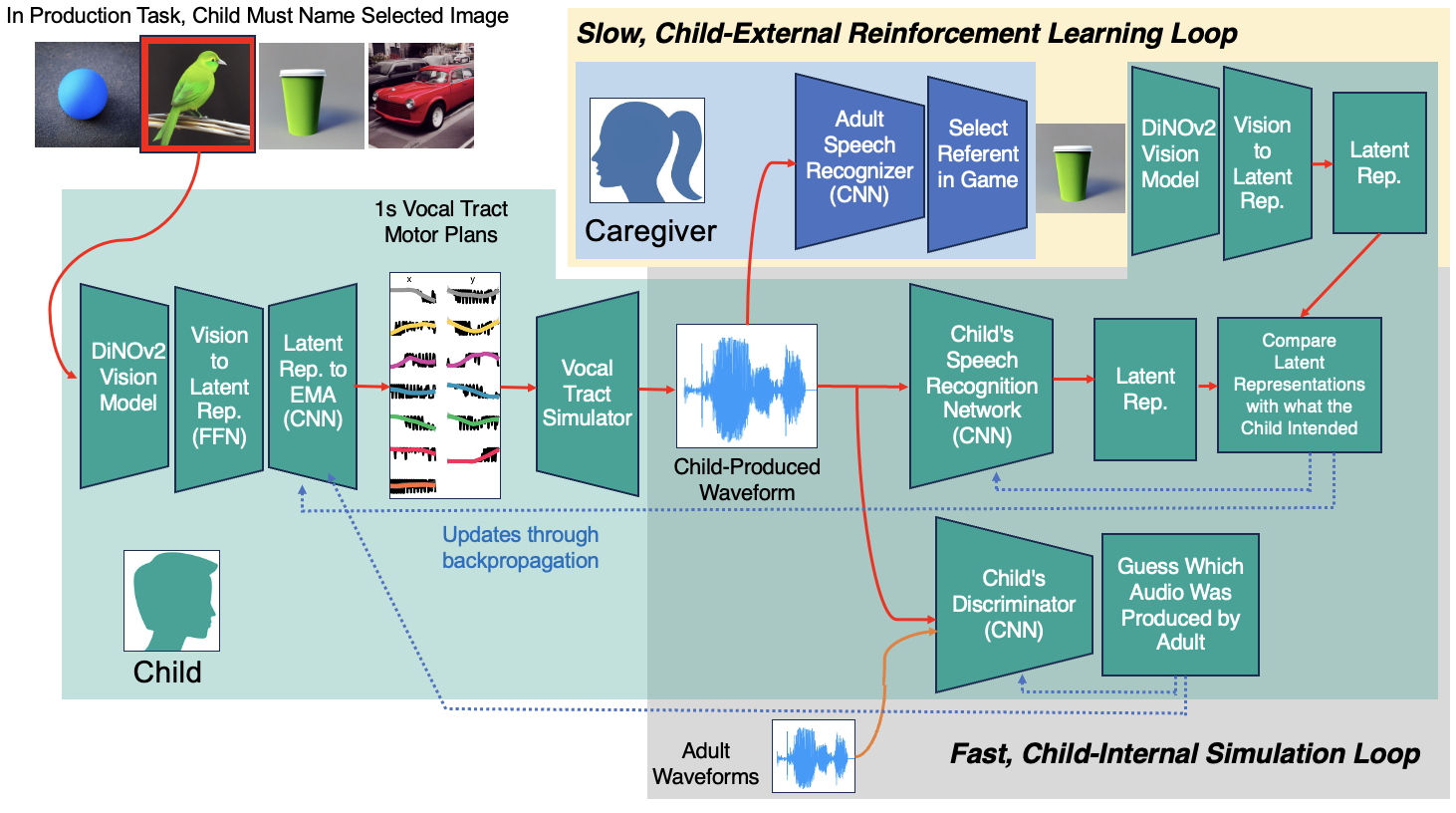
A Multitask, Multimodal Neural Language Learner Recharacterizing the challenge of early communication with the above work invites new models of child language learning. In this work, we explore symbol-free hierarchical reinforcement learning to drive a model vocal tract to name images as processed by an unsupervised vision network. Using “self-play” methods where the child language learning model revises its knowledge of words and articulations by practicing against its own speech recognition system, this model learns to recognize speech and produce speech from a vocal tract model. Hierarchical representations in the model—a convolutional neural net—replicate long-standing units of linguistics representation. Joint work with Dr. Roger Levy and Dr. Gasper Begus.
Early Linguistic Productivity
When do children start to develop abstract representations of language structure? To what degree do these representations mirror the categories used in linguistic description?
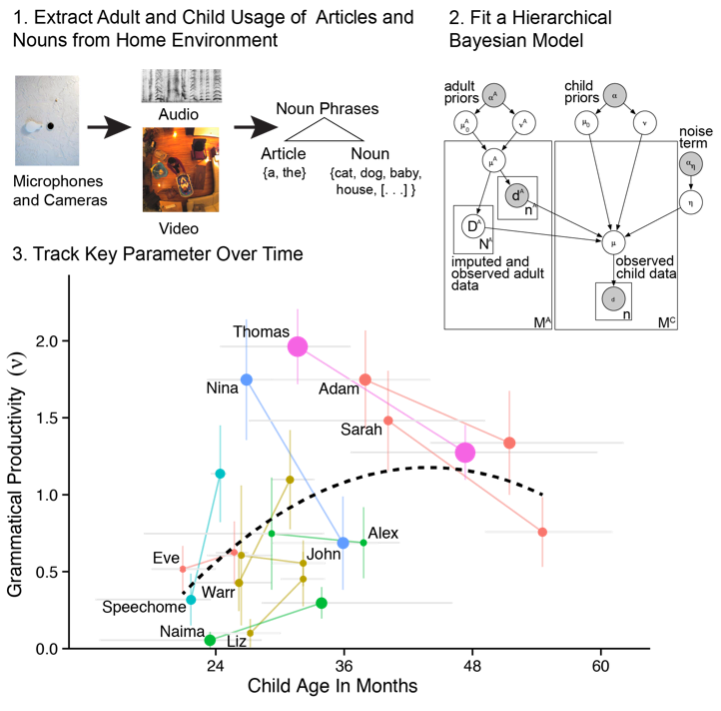
Children’s Acquisition of Syntax In this paper, we use a hiererchical Bayesian model to look for evidence of grammatical generalization in children’s earliest use of articles (“a”, “an,” and “the”).
The model, when applied to a large set of longitudinal, developmental corporal, yields evidence of minimal generalization before two years of age, but a rapid increase thereafter.
Joint work with Dr. Michael C. Frank, Dr. Roger Levy, and Brandon Roy.
Meylan, S.C., Frank, M.C., Roy, B.C., and Levy, R. (2017). The emergence of an abstract grammatical category in children’s early speech. Psychological Science, 28 (2), pp. 181–192. (pdf)
Children’s Acquisition of Morphology While English-learning children begin using the regular plural (+s) in their everyday speech around 20 months, it is less clear whether they use the plural in an adult-like way.
In this study, we systematically test both what children say as well as what they understand from the speech of others in a lab-based eyetracking experiment.
We find that children successfully apply a +s rule to derive novel plurals (nops, teps) long before mastering familiar plurals (cats, dogs, etc.), suggesting that generalizations emerge early and play a part in the processes of word learning. Joint work with Dr. Roger Levy and Dr. Elika Bergelson.
Meylan, S.C., Levy, R.P., and Bergelson, E. (2020). Children’s Expressive and Receptive Knowledge of the English Regular Plural. In Proceedings of the 42nd Annual Meeting of the Cognitive Science Society. (pdf, 5-min talk on YouTube)
![]()
Robust Speech Processing in Adults
What expectations do adults use when understanding the speech of other adults? One way to characterize these expectations (technically, Bayesian priors) is to have participants play a large game of ``telephone,’’ which is mathematically guaranteed to elicit responses that transition towards and eventually converge with the prior! This work provides evidence that expectations regarding syntactic structures inform adult word recognition. I also discuss how corpora are not necessarily representative of adult expectations, contrary to the premises of almost all existingg work. Joint work with Sathvik Nair and Dr. Tom Griffiths.
Meylan, S., Nair, S., and Griffiths, T. (2021). Evaluating models of robust word recognition with serial reproduction. Cognition. (link)
One Word, Multiple Meanings
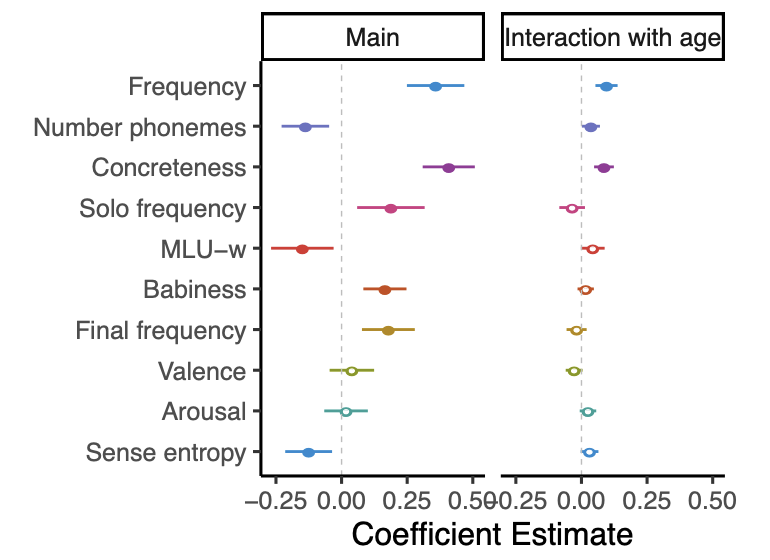
Words often sustain multiple meanings; sometimes these combinations of meanings are conceptually motivated (i.e., using the same word to refer to an animal and its meat like chicken), while sometimes they are not (bat as sports equipment vs. a flying mammal). How children come to parse apart and systematically extend these meanings is largely unknown. As a first step Jess Mankewitz, Dr. Sammy Floyd, Dr. Mahesh Srinivasan, Dr. Hugh Rabagliati, and I have collected the first large-scale child language dataset annotated with categorical meanings. We have found that children indeed produce fewer meanings per word than adults, though they do produce multiple meanings even among their earliest speech. We find no evidence that adults use fewer meanings when talking to children than when talking to children. We also find that children are likely to use words with more disparate sense usage later than those with more consistent sense usage.
Meylan, S.C., Mankewitz, J., Floyd, S., Rabagliati, H., and Srinivasan, M. (2021). Quantifying Lexical Ambiguity in Speech To and From English-Learning Children. In Proceedings of the 43rd Annual Meeting of the Cognitive Science Society. (link)
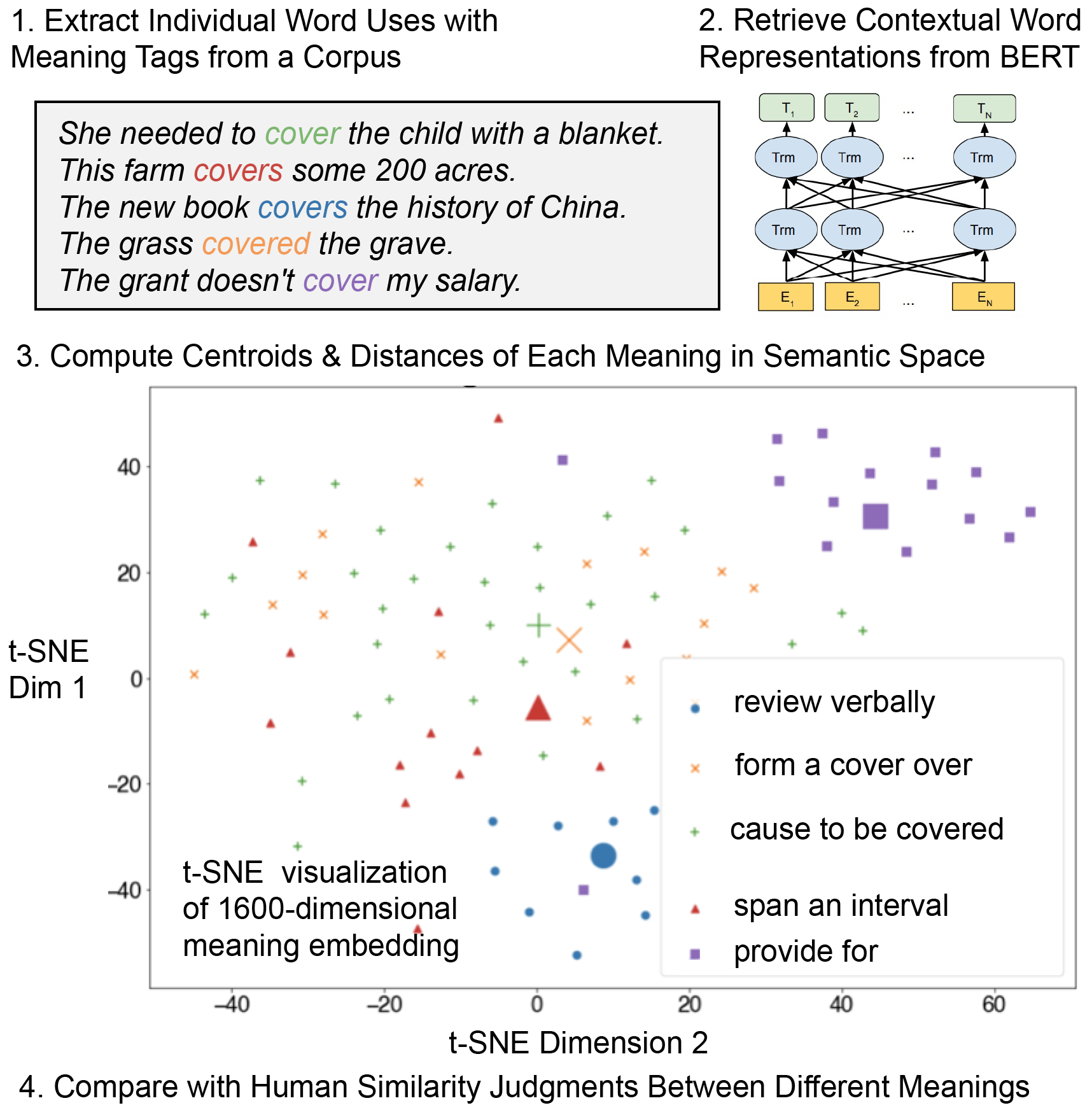
In a related line of work, I have been investigating the prospects for reconciling dictionary and continuous/vector-space representations of word meanings, and using contextualized word representations from recent neural models as a better model of the space of human meanings, especially semantic generalization.
Nair, S., Srinivasan, M., and Meylan, S.C. (2020). Contextualized Word Embeddings Encode Aspects of Human-Like Word Sense Knowledge. Proceedings of the Workshop on the Cognitive Aspects of the Lexicon (CogALex / COLING). (link)
Linguistic Universals and Cognitive Pressures
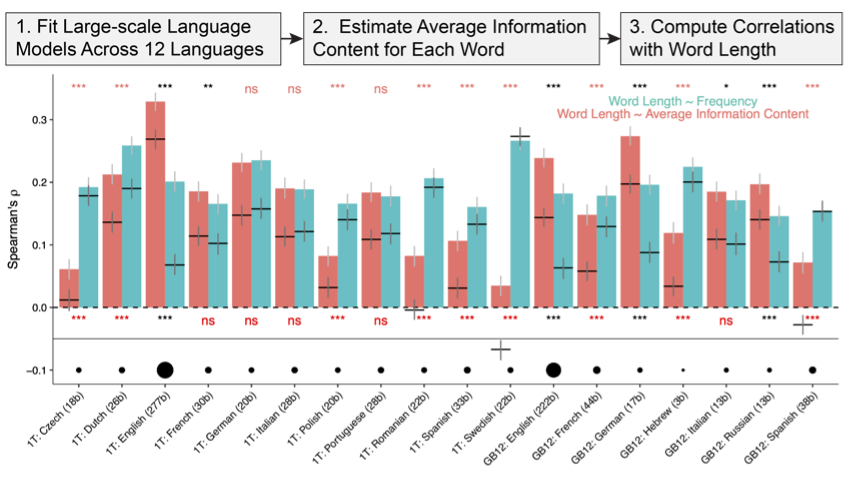
A recent prominent result (Piantadosi et al., 2011) found a stronger correlation between word lengths and predictability given preceding words than the long-known relationship between a word’s length and its use frequency (Zipf, 1935).
In Meylan & Griffiths (2021, Cognitive Science), I showed that their results emerge from a statistical paradox (Simpson’s paradox), and that the conclusions don’t hold once more robust corpus processing methods and statistical controls are used.
In a related piece (Meylan & Griffiths, “Word forms reflect trade-offs between speaker effort and robust listener recognition”, under review), I showed that the probability of the sound sequences that make up a word, rather than its length in terms of sounds, is the stronger correlate of predictability. This is in part because sound sequences capture historical sound change in more nuanced ways than word length does.
Tools for Studying Early Language Acquisition
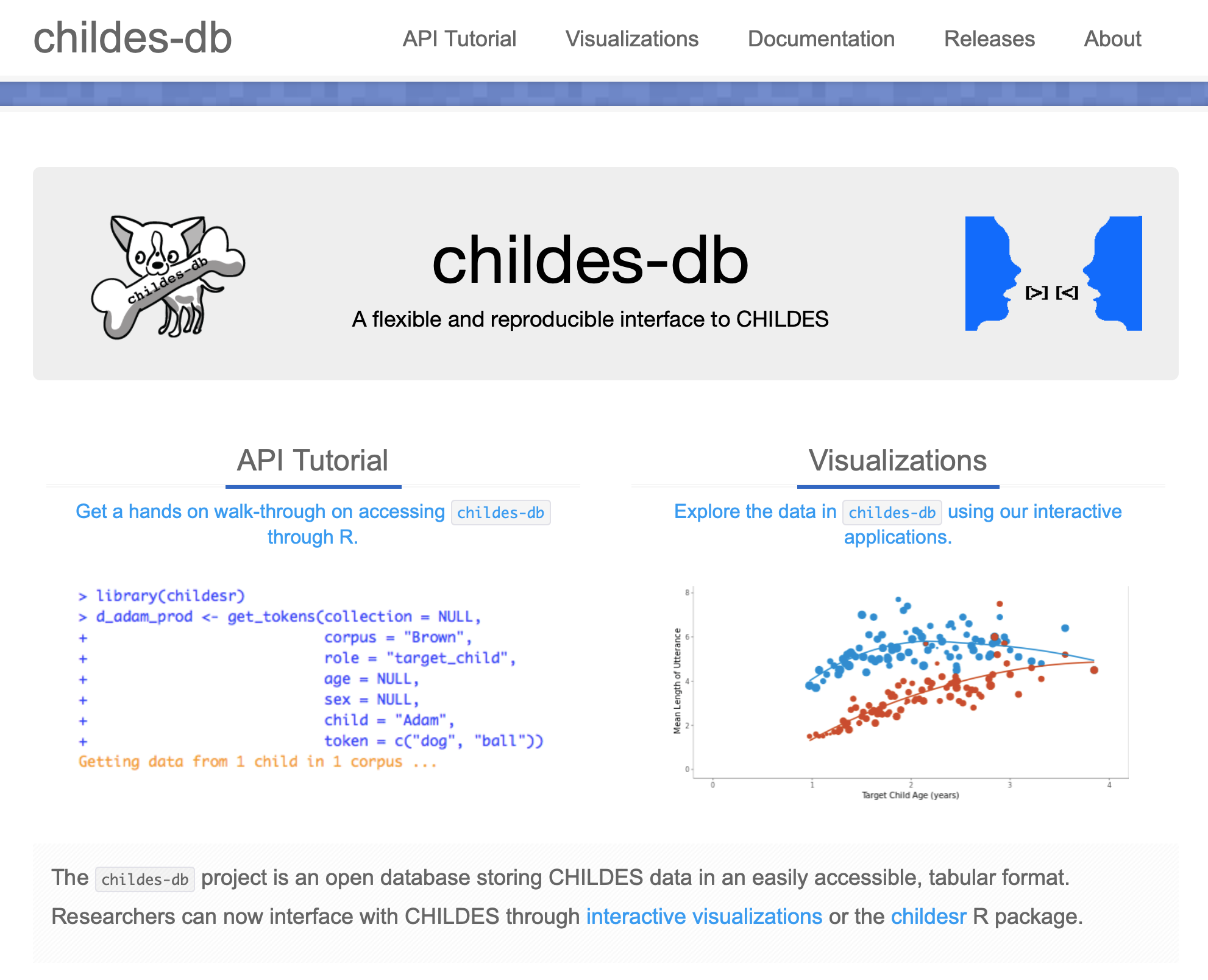
childes-db is a set of software tools for cognitive scientists, psychologists, and linguists who want to work with child language corpora in the Child Language Data Exchange System (CHILDES). childes-db provides a versioned set of reference parsings, direct MySQL access, an R API, and web-based visualizations for many common tasks. Joint work with Alessandro Sanchez, Mika Braginsky, Kyle MacDonald, Dr. Dan Yurovsky, and Dr. Michael C. Frank.
*Sanchez, A., *Meylan, S.C., Braginsky, M., MacDonald, K.E., Yurovsky, D., and Frank, M.C. (2019). childes-db: A flexible and reproducible interface to the child language data exchange system. Behavior Research Methods, 51 (4), pp. 1928–1941. (pdf)
*co-first authorship
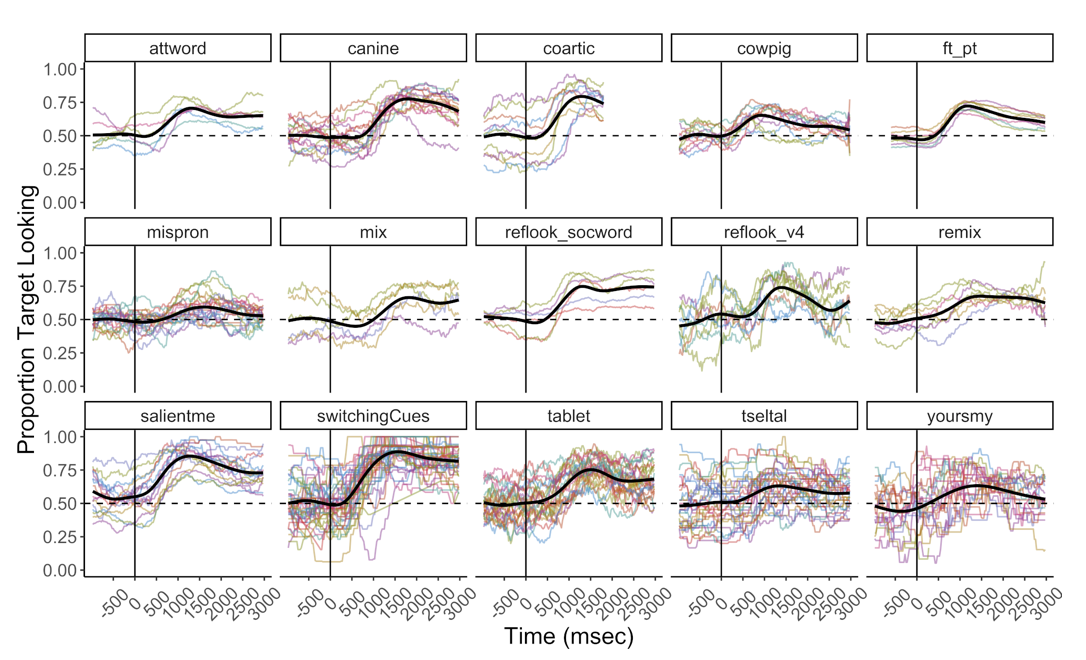
Peekbank is a data repository and set of software tools for gazetracking data testing early vocabulary knowledge. Peekbank puts 20+ eyetracking and gazetracking studies into a common interchange format, and gives researchers an R API, direct MySQL access, and web-based visualizations for many common tasks. We are using this dataset now to parameterize new models of early word learning. My role in this project is something akin to the chief technical officer. Joint work with like a million people.
Zettersten, M., Yurovsky, D., Xu, T.L., Uner, S., Tsui, A., Schneider, R.M., Saleh, A., Meylan, S.C., Marchman, V.A., Mankewitz, J., MacDonald, K., Long, B., Lewis, M., Kachergis, G., Handa, K., deMayo, B., Carstensen, A., Braginsky, M., Boyce, V., Bhatt, N., Bergey, C., and Frank, M.C. (under review). Peekbank: An open, large-scale repository for developmental eye-tracking data of children’s word recognition.
Wordful is a smartphone app for tracking early vocabulary growth. Wordful builds on proven checklist-based methods to support more engaging, high-touch longitudinal studies of language acquistion, with model-based sampling logic. Multiple caregivers can contribute data for the same child, and each caregiver can contribute data to multiple children. A powerful scheduling and templating system means that the app is highly extensible, and can be customized for many kinds of longitudinal studies of language development.
Meylan, S., Braginsky, M., DeMayo, B., Sanchez, A., Schonberg, C., Srinivasan, M., Vlach, H., Lupyan, G., Griffiths, T., and Frank, M. (2019). Wordful : Tracking Early Productive Vocabulary Growth With Smartphones. 44th Annual Boston University Conference on Language Development. (pdf)